Performance analysis of Java loop variants
What is the fastest loop variant? Does it even matter?
From time to time I profile Gaia Sky to find CPU hot-spots that are hopefully easy to iron out. To do so, I launch my profiler of choice and look at the CPU times for the top offender methods. Today I went through such a process and was surprised to find a forEach() method of the Java streams API among the worst offenders. Was the forEach() slowing things down or was it simply that what’s inside the loop took too long to process? I found conflicting and inconsistent reports in the interwebs, so I set on a quest to provide my own answers.
The idea is very simple. We’ll use statistics and brute force through gazillions of loop cycles using the different loop variants to produce statistically significant data. Then, we’ll compare the different loop variants and decide whether it is worth using one over the others or not.
Loop variants
First of all, what loop variants will we be looking at? Well, the most common are the for loop, the while loop, the forEach() from the streams API, the explicit iterator and the implicit iterator.
For loop
The classic C-style for loop. I like to think that every human in existence has used this at some point in her life.
for (int i = 0; i < array.size(); i++) {
Byte s = array.get(i);
}
While loop
The classic, well-known while loop.
int i = 0;
while (i < array.size()) {
Byte s = array.get(i);
i++;
}
For-each stream
The forEach() method from the streams API. This is very compact and not using it requires some extra willpower.
array.forEach((s) -> {});
Iterator
An explicit iterator. Ugly, ugly.
Iterator<Byte> iterator = array.iterator();
while (iterator.hasNext()) {
Byte next = iterator.next();
}
Implicit iterator
This for loop uses an iterator implicitly under the hood.
for (Byte next : array) {}
The code
I set up a repository with the code I’m gonna be using to run the tests. The utility in question computes the CPU and wall-clock times (plus standard deviation) of the different loop variants using a configurable number of rounds and iterations per round, after a warm-up period. The warm-up period defaults to 5 million iterations per variant, and is used to allow the JIT compiler to optimize the code if needed before the actual test. The number of rounds and iterations can also be passed in as CLI arguments. Check out the repository README.md file for more information.
For instance, if you want to run the tests with 20 rounds and 500 million iterations per round, you’d run(after building and extracting the distribution package):
bin/loopperformance 500000000 20
That would use the default JRE in your $JAVA_HOME. If you want to run with a different JRE, you just need to set the value of the variable before running:
JAVA_HOME=/path/to/jre && bin/loopperformance 500000000 20
Results
We come to the interesting part. A wide variety of factors have an effect on the test results. The CPU brand and model, the JVM version and parameters, the GC algorithm, or the operating system, just to name a few. In my case, I ran all tests with a machine with Arch Linux, an Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz processor and 32 Gb or RAM.
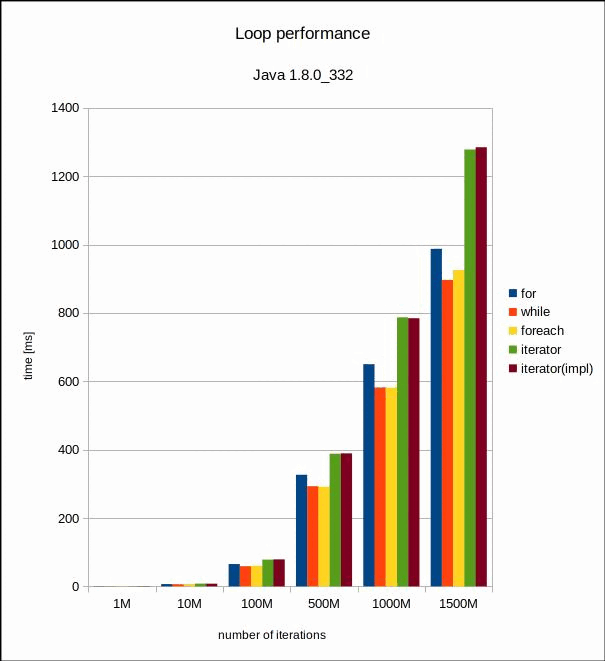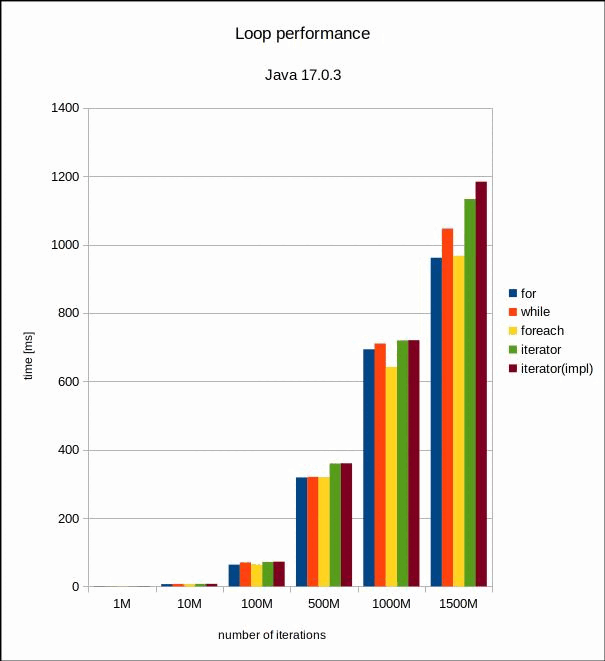
Each test uses 50 million warm-up iterations, and then 20 rounds for 1, 10, 100, 500, 1000 and 1500 million iterations for each of the test variants. OpenJDK Runtime Enviornment 17.0.3+3 has been used for this first batch.
Java 17
First we’ll run with the fairly recent Java 17. This should give us a good estimate of the differences between the different loop variants in modern Java.
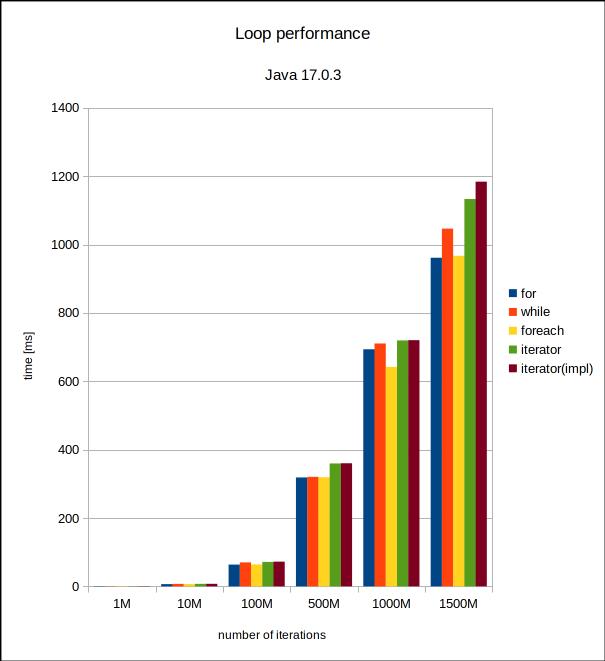 Wall-clock time in milliseconds for the six iteration counts and Java 17. | 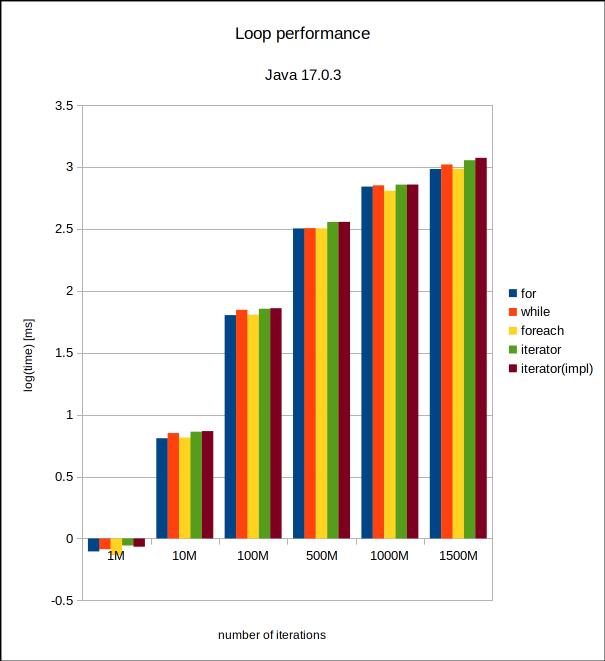 Same plot with a logarithmic scale. |
Apparently, we need to go to very high iteration counts (over a thousand million) to encounter statistically significative differences between for, while, for-each and the two iterators. The iterators seem to be the slowest, with the implicit variant faring a bit worse. However, this is only the case in the 1500 million iterations. The total differences are in the order of a couple hundred milliseconds, which is almost negligible, especially considering that these loops do absolutely nothing. I would expect that adding some logic in the loops would completely dominate the times, so we can conclude that with Java 17 it makes no significant difference what loop variant we use in terms of processing time.
Java 8
As a point of comparison, we’ll run the same tests with Java 8, which came out some 8 years ago. Let’s see.
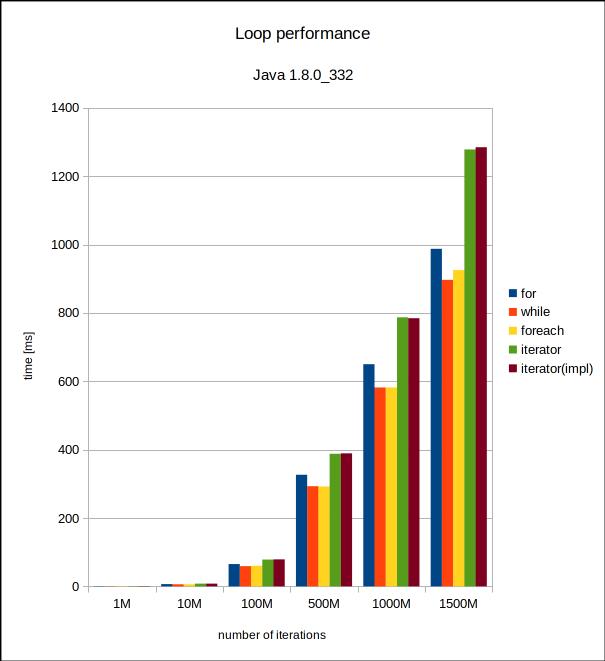 Wall-clock time in milliseconds for the six iteration counts and Java 8. | 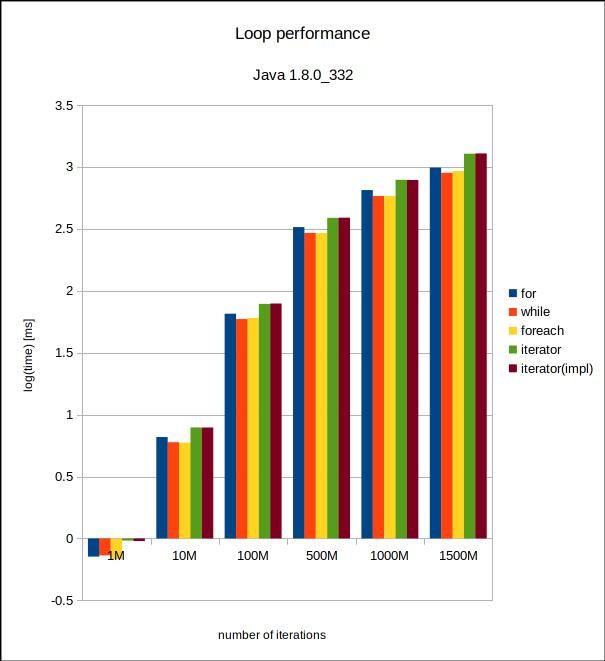 Same plot with a logarithmic scale. |
Woah. Right off the bat, we see that the performance of iterators has improved a lot between Java 8 and 17. Also, we see that for, while and forEach() are all almost always FASTER in Java 8! That is surprising and unexpected. I’m not sure what the reason for that is, but it could be attributed to runtime noise, since the differences are not very large. In Java 8 it may make more sense to avoid using iterators for very performance critical applications that iterate on stuff all the time. Otherwise, I think that this won’t make much difference in a production environment. The rest of the application will also clearly dominate performance here, with an impact orders of magnitude larger than what the different loop variants might have.
Below is an animated gif to better compare the results of Java 17 vs Java 8.
Animation comparing the performance results between Java 8 and Java 17.
Final notes
You can find the raw data and the spreadsheets in the results directory of the project.
Conclusion
To sum up, do not worry about what loop variant you use. The performance impact of the different variants is most definitely negligible. The JIT compiler is able to optimize the code enough so that the differences are virtually non-existent. Additionally, iterators in modern Java versions are almost on par with the other, more direct loop schemes.